精细化运营数据分析方法之——用户画像搭建
时间:2021-05-18来源:亿信ABI知识库浏览数:373次
提到用户画像, 很多人都可能存在的错误认知,即把用户画像简单理解成用户各种特征,比如说姓名、性别、职业、收入、养猫、喜欢美剧等等。这些特征表面上看没有什么问题,但是实际上组成用户画像要跟业务/产品结合。
比如,海底捞要做用户画像,最后列出来小明是一个大学生、高富帅、独生子、四川人,爱玩游戏、爱看动漫等用户标签。而事实上,对于海底捞而言,用户帅不帅、是否爱玩游戏真的没有关系。
因此对很多企业来说,搭建的用户画像标签并没有真正起到有效的作用。那到底什么是用户画像,用户画像对企业来说主要用在什么地方?以及企业该如何搭建一套有效的用户画像?今天小亿就来为大家分享一下。
一、什么是用户画像?
1.定义
用户画像即用户信息标签化,通过收集用户的社会属性、消费习惯、偏好特征等各个维度的数据,进而对用户或产品特征属性进行刻画,并对这些特征进行分析、统计,挖掘潜在价值信息,从而抽象出用户的信息全貌。
用户画像包含的内容并不完全固定,根据行业和产品的不同所关注的特征也有不同。对于大部分公司,可以从用户特征、业务场景和用户行为三个方面构建一个标签化的用户模型。
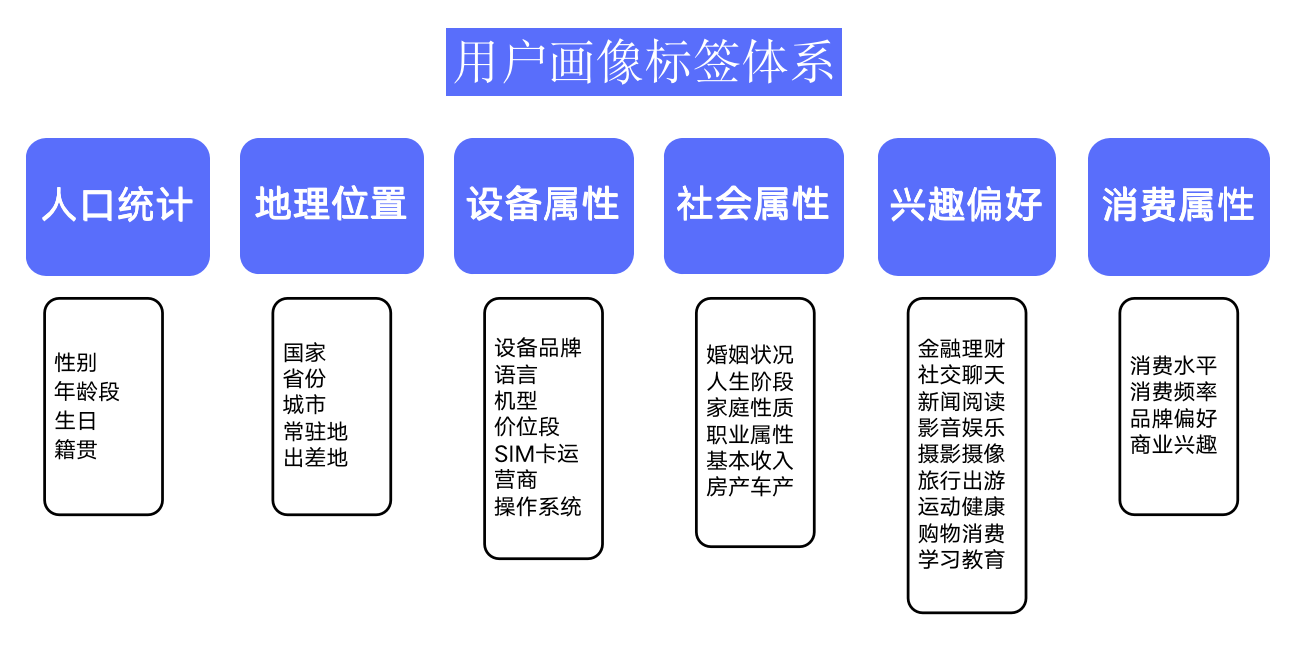
2.类型
(1)统计类标签
这类标签是最为基础也最为常见的标签类型,例如:对于某个用户来说,其姓名、性别、年龄、地市、活跃时长等,这类数据可以从用户注册数据、用户消费数据中得出,该类数据构成了用户画像的基础。
(2)规则类标签
基于用户的行为以及规则,在实际开发画像的过程中,由于运营人员对业务更为熟悉,而数据人员对数据的结构、分布、特征更为熟悉,因此规则类标签的规则由运营人员和数据人员共同协商确定
(3)学习挖掘类标签
通过机器学习挖掘产生,根据用户的行为和规则进行预测和判断。比如某个用户购买卫生巾,我们可以通过这个行为来推出用户性别为女性、根据一个用户的消费习惯判断其对某商品的偏好程度。该类标签需要通过算法挖掘产生。
在项目工程实践中,一般统计类和规则类的标签即可以满足应用需求,在开发中占有较大比例。机器学习挖掘类标签多用于预测场景,如判断用户性别、用户购买商品偏好、用户流失意向等。一般地,机器学习标签开发周期较长,开发成本较高,因此其开发所占比例较小。
二、用户画像主要的作用是什么?
全域场景下,用户画像的应用通常是基于大数据平台进行数据采集分析,把用户标签按不同模块进行归类后提供给产品、运营或分析师使用,应用场景涵盖金融风控、精准营销、个性化推荐等,应用方向包括活动人群筛选、用户洞察报告、营销决策系统、推荐系统等。
1.精准营销
在如今流量红利消失殆尽,企业全面进入精细化运营时代,用户画像可以帮助我们理解用户并为其提供精准服务或个性化服务。比如,某个电商平台需要做个活动给不同的层次的用户发放不同的券, 那么我们就要利用用户画像对用户进行划分,划分成不同的付费的活跃度的用户, 然后根据不同的活跃度的用户发放不用的优惠券,从而提高运营效率。
2.用户洞察
用户画像也是了解用户的必要补充。产品早期,产品经理们通过用户调研和访谈的形式了解用户。在产品用户量扩大后,调研的效用降低,这时候就可以辅以用户画像配合研究。方向包括新增的用户有什么特征,核心用户的属性是否变化等等。
除此以外,用户画像可以理解为业务层面的数据仓库,各类标签是多维分析的天然要素。数据查询平台会和这些数据打通,最后辅助业务决策。
3.产品设计
相比过去较为传统的企业生产什么就卖什么,如今“用户需要什么企业就生产什么”成为主流,于是许多企业把用户真实的需求摆在了最重要的位置。
在用户需求为导向的产品研发中,企业通过获取到的大量目标用户数据,进行分析、处理、组合。初步搭建用户画像,做出用户喜好、功能需求统计,从而设计制造更加符合核心需要的新产品,为用户提供更加良好的体验和服务。
4.数据应用
用户画像是很多数据产品的基础,诸如耳熟能详的广告系统,广告基于一系列人口统计相关的标签,性别、年龄、学历、兴趣偏好、手机等等来帮助企业进行进行推广投放的。
除此以外,还有个性化推荐,比如我们在音乐app上看到的每日推荐,网易云之所以推荐这么准,就是他们在做点击率预估模型(预测给你推荐的歌曲你会不会点击)的时候, 考虑了你的用户画像属性。比如根据你是90后,喜欢伤感的,又喜欢杰伦,就会推荐类似的歌曲给你,这些就是基于用户画像推荐。
最后还有风控检测,这个主要是金融或者银行业涉及的比较多, 因为经常遇到的一个问题就是银行怎么决定要不要给一个申请贷款的人给他去放贷。经常的解决方法就是搭建一个风控预测模型,去预测这个人是否会不还贷款,同样的,模型的背后很依赖用户画像。用户的收入水平,教育水平,职业,是否有家庭,是否有房子,以及过去的诚信记录,这些的画像数据都是模型预测是否准确的重要数据。
三、企业该如何搭建一套有效的用户画像?
1.明确用户画像的目的
确认用户画像目的是非常基础也是关键第一步,要了解构建用户画像期望达到什么样的运营或营销效果,从而在标签体系构建时对数据深度、广度及时效性方面做出规划,确保底层设计科学合理。
2.数据的收集与处理
在采集数据时,需要考虑多种维度,比如行业数据、全用户总体数据、用户属性数据、用户行为数据、用户成长数据等等,并通过行业调研、用户访谈、用户信息填写及问卷、平台前台后台数据收集等方式获得。
对于一般公司而言,更多是根据系统自身的需求和用户的需要收集相关的数据。数据收集主要包括用户行为数据、用户偏好数据、用户交易数据。
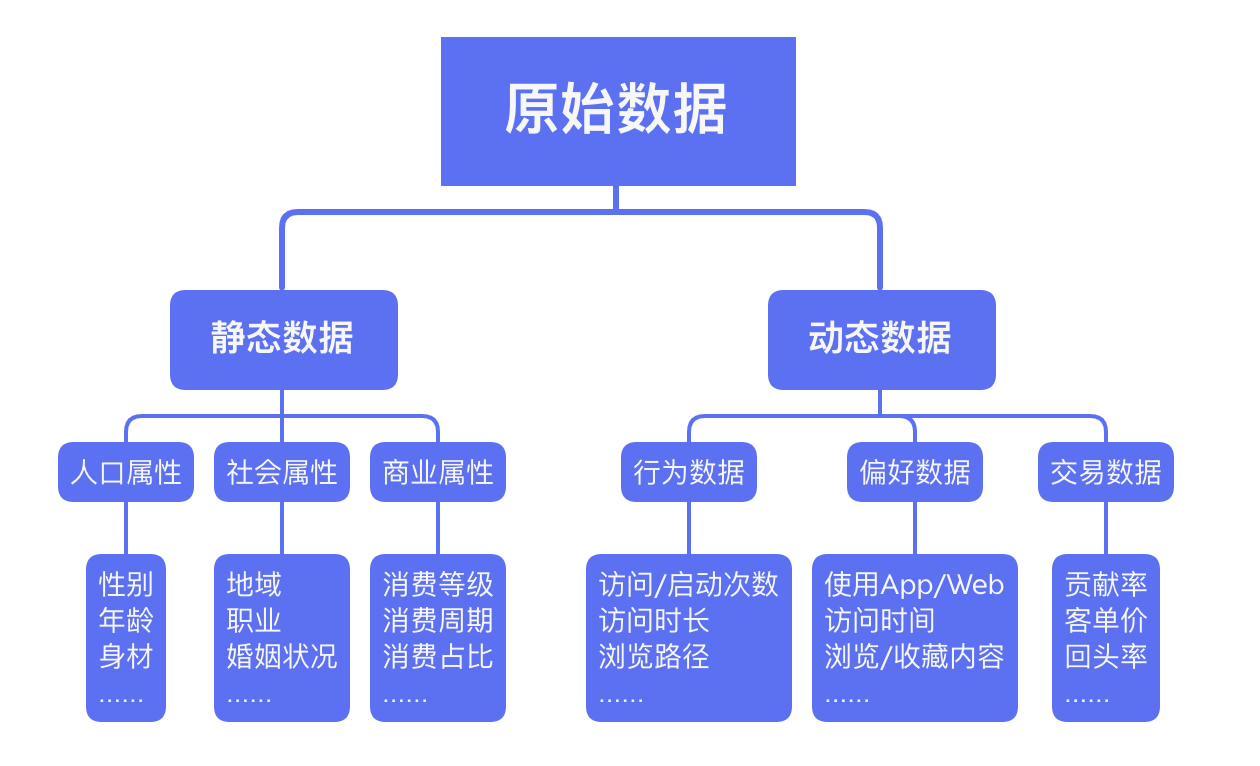
除此以外,就自身平台采集到的数据,还可能存在非目标用户、无效数据及虚假数据,因此企业还需要对数据进行清洗,解决数据空缺、虚假、重复、错误等问题,为了保证后期挖掘的准确性,避免对结果造成影响。之后我们可对收集的数据做分析,让用户信息形成标签化。比如搭建用户账户体系,可自建立数据仓库,实现平台数据共享,或打通用户数据。
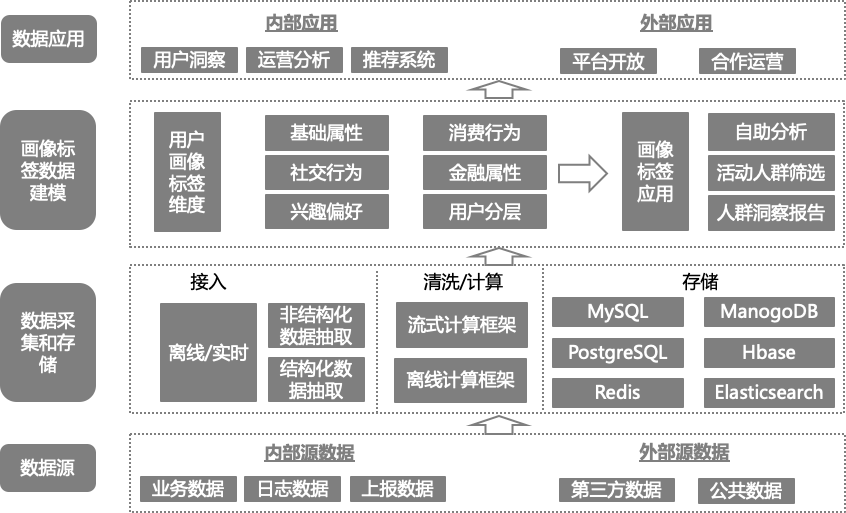
3.数据标签化
在这一步企业将得到的数据映射到构建的标签中,并将用户的多种特征组合到一起。标签的选择直接影响最终画像的丰富度与准确度,因而数据标签化时需要与产品自身的功能与特点相结合。
如电商类APP需要对价格敏感度相关标签细化,而资讯类则需要尽可能多视角地用标签去描述内容的特征。
常见的标签分成两大类别:相对静止的用户标签以及变化中的用户标签。相对应的,由静态标签搭建形成的画像就是2D用户画像;由静态标签+动态标签构建出来的即是3D用户画像。
还得一提的是,储存用户行为数据时最好同时储存下发生该行为的场景,以便更好地进行数据分析。
(1)静态的用户信息标签以及2D用户画像
人口属性标签是用户最基础的信息要素,通常自成标签,不需要企业过多建模,它构成用户画像的基本框架。人口属性包括人的自然属性和社会属性特征:姓名、性别、年龄、身高、体重、职业、地域、受教育程度、婚姻、星座、血型……自然属性具有先天性,一经形成将一直保持着稳定不变的状态,比如性别、地域、血型;社会属性则是后天形成的,处于相对稳定的状态,比如职业、婚姻。
心理现象包括心理和个性两大类别,同样具有先天性和后天性。对于企业来说,研究用户的心理现象,特别是需求、动机、价值观三大方面,可以窥探用户注册、使用、购买产品的深层动机;了解用户对产品的功能、服务需求是什么;认清目标用户带有怎样的价值观标签,是一类什么样的群体。因为人口属性和心理现象都带有先天的性质,整体处于稳定状态,共同组成用户画像最表面以及最内里的信息素,由此形成稳定的2D用户画像。
(2)动态的用户信息标签以及3D用户画像
比如这里我们主要讨论的是用户在网站内外进行的一系列操作行为。常见的行为包括:搜索、浏览、注册、评论、点赞、收藏、打分、加入购物车、购买、使用优惠券......在不同的时间,不同的场景,这些行为不断发生着变化,它们都属于动态的信息。
企业通过捕捉用户的行为数据(浏览次数、是否进行深度评论),可以对用户进行深浅度归类,区分活跃/不活跃用户。社交网络行为,是指发生在虚拟的社交软件平台(微博、微信、论坛、社群、贴吧、twitter、Instagram)上面一系列用户行为,包括基本的访问行为(搜索、注册、登陆等)、社交行为(邀请/添加/取关好友、加入群、新建群等)、信息发布行为(添加、发布、删除、留言、分享、收藏等)。
给用户打上不同的行为标签,可以获取到大量的网络行为数据、网站行为数据、用户内容偏好数据、用户交易数据。这些数据进一步填充了用户信息,与静态的标签一起构成完整的立体用户画像,就是所说的3D用户画像。
4.绘制用户画像
(1)定性与定量相结合的研究方法
一般来说,定性的方法,在用户画像中,表现为对产品、行为、用户个体的性质和特征作出概括,形成对应的产品标签、行为标签、用户标签。定量的方法,则是在定性的基础上,给每一个标签打上特定的权重,最后通过数学公式计算得出总的标签权重,从而形成完整的用户模型。
(2)数据建模——给标签加上权重
给用户的行为标签赋予权重。用户的行为,我们可以用4W表示:WHO(谁);WHEN(什么时候);WHERE(在哪里);WHAT(做了什么),具体分析如下:
①WHO(谁):定义用户,明确我们的研究对象。主要是用于做用户分类,划分用户群体。网络上的用户识别,包括但不仅限于用户注册的ID、昵称、手机号、邮箱、身份证、微信微博号等等;
②WHEN(时间):这里的时间包含了时间跨度和时间长度两个方面。“时间跨度”是以天为单位计算的时长,指某行为发生到现在间隔了多长时间;“时间长度”则为了标识用户在某一页面的停留时间长短。越早发生的行为标签权重越小,越近期权重越大,这就是所谓的“时间衰减因子”;
③WHERE(在哪里):就是指用户发生行为的接触点,里面包含有内容+网址。内容是指用户作用于的对象标签,比如小米手机;网址则指用户行为发生的具体地点,比如小米官方网站。权重是加在网址标签上的,比如买小米手机,在小米官网买权重计为1,在京东买计为0.8,在淘宝买计为0.7;
④WHAT(做了什么):就是指的用户发生了怎样的行为,根据行为的深入程度添加权重。比如,用户购买了权重计为1,用户收藏了计为0.85,用户仅仅是浏览了计为0.7。
当上面的单个标签权重确定下来后,就可以利用标签权重公式计算总的用户标签权重:标签权重=时间衰减因子×行为权重×网址权重。举个栗子:A用户今天在小米官网购买了小米手机;B用户七天前在京东浏览了小米手机。由此得出单个用户的标签权重,打上“是否忠诚”的标签。
通过这种方式对多个用户进行数据建模,就能够更广的覆盖目标用户群,为他们都打上标签,然后按照标签分类:总权重达到0.9以上的被归为忠实用户,他们都购买了该产品......这样一来,企业和商家就能够根据相关信息进行更加精准的营销推广、个性化推荐。
四、构建用户画像需要注意的关键点
1.所有数据要建立在真实的、准确的、全量的、实时的数据之上
影响用户画像的最终呈现的数据有很多,我们要选择线上的实时的数据来做洞察,相较于线下导入的数据,线上数据更直观,也更真实;其次,线上的数据能够覆盖更多、更全面的端口,来充分记录一个用户的多种行为。
2.标签并不是维度越多、越广泛就一定是最好的
数据量不断扩充,用户画像也会越来越细,越来越多,供我们参考的信息也越多,但是数据的存在是为了形成洞察,洞察的结果是为了指导业务。因此多个用户画像存在的时候,我们一定要制定核心画像和进行优先级排序,跟核心业务路径转化最相关的,作为我们最重视的画像来指导业务。
3.用户画像是需要不断迭代和修正的
用户画像终其根源是人的画像,人的属性,人是复杂的,是动态变化的,因此在真实的业务环境中,一个用户的等级可以逐渐攀升,行为确是多种变化,所以我们做画像的规则也需要动态适应这种变化。
五、小结
用户画像发展至今,可用性已经得到了一步步的提升。当企业以庞大的用户数据为依托,借助其标签化、信息化、可视化的属性,构建出一整套完善的用户画像,就可以进一步通过数据来识别与预判经营的风险。
与此同时,用户画像应以最终业务目标为指导来进行构建,不同业务想刻画出来的用户群体是有差异的,只有选择对业务有价值的标签来刻画用户才能更好的应用在业务层面,实现真正意义上的千人千面。
最后在落地运行用户画像的过程中还需要开发标签的数据工程师和需求方相互协作,将标签应用到业务中。否则开发完标签后,数据还是只停留在数据仓库中,没有为业务决策带来积极作用。
-

用数据分析助力企业决策与业务创新
发布时间:2023-09-26浏览量:286次
在数字化时代,数据分析已经成为企业成功的关键因素之一。作为国内领先的数据分析厂商,亿信华辰一直致力于为各类企业提供最优质的数据分析产品和...查看详情 -

为什么要学习数据分析?数据分析产出是什么?
发布时间:2022-06-28浏览量:1334次
「过去」以往在增量时代,每天都有新的领域、新的市场被开发。尤其是在互联网、电商等领域的红利期,似乎只要做好单点的突破就能获得市场。这个蛮...查看详情 -

数据分析很痛苦?5个对策、8大方法帮到你!
发布时间:2022-06-15浏览量:496次
“对数据敏感,能够通过数据分析与反馈,不断改进和优化产品”之类的招聘要求屡见不鲜。诚然,数据分析能力已经成为产品经理不可或缺的技能。数据...查看详情 -

浅谈大数据的过去、现在和未来
发布时间:2022-06-14浏览量:841次
相信身处于大数据领域的读者多少都能感受到,大数据技术的应用场景正在发生影响深远的变化: 随着实时计算、Kubernetes 的崛起和 HTAP、流批一体...查看详情 -

数字经济时代,企业的核心竞争力究竟是什么?
发布时间:2022-06-14浏览量:1118次
数字经济时代对于企业而言意味着全新的挑战和机遇,如何抓住数字经济的本质,而不是停留在各种零碎的、华丽的词藻堆砌,构建企业核心竞争力新的理...查看详情

